

How to Architect an Enterprise-Grade AI Agent Securely
Going Beyond the Single Process Problem


During my week by the pool I've been going deep into the architecture of AI agents.
Yes, I am that much fun on holiday.
What I've noticed something pretty worrying: while everyone's busy talking about capabilities and features (and posting endlessly about which LLM is the best 🙄), security and safety are pretty much afterthoughts for most AI agent system.
After watching Don Bosco Durai's insights on AI agent security, I'm convinced that the next battleground in AI agent adoption isn't just capabilities—it's trust.
And without proper security patterns, trust is impossible.
The Uncomfortable Truth About AI Agents
Let's start with a truth most LinkedIn "experts" won't tell you: Most AI agent frameworks today run in a single process environment. This means agents, tasks, and tools all share the same memory space, credentials, and privileges.
Think about that for a second.
If your agent needs to access a database, it typically uses service credentials with admin-level privileges. Any third-party library in that process can potentially access those same credentials. As Durai aptly puts it, this creates a "zero trust issue" that makes the entire environment fundamentally insecure.
And there's another, more profound challenge that makes AI agent security uniquely difficult: agents are, by definition, autonomous and non-deterministic.
Unlike traditional software where you can map out all possible execution paths, AI agents create their own workflows dynamically. This introduces what security professionals call "unknown unknowns"—potential vulnerabilities you didn't even know existed because you can't predict what the agent might decide to do.
The Security Trinity for AI Agents
After digesting Durai's insights and comparing them with my own experiences, we see a Security Trinity for AI Agents—three layers of protection that any production-grade agent system must implement:
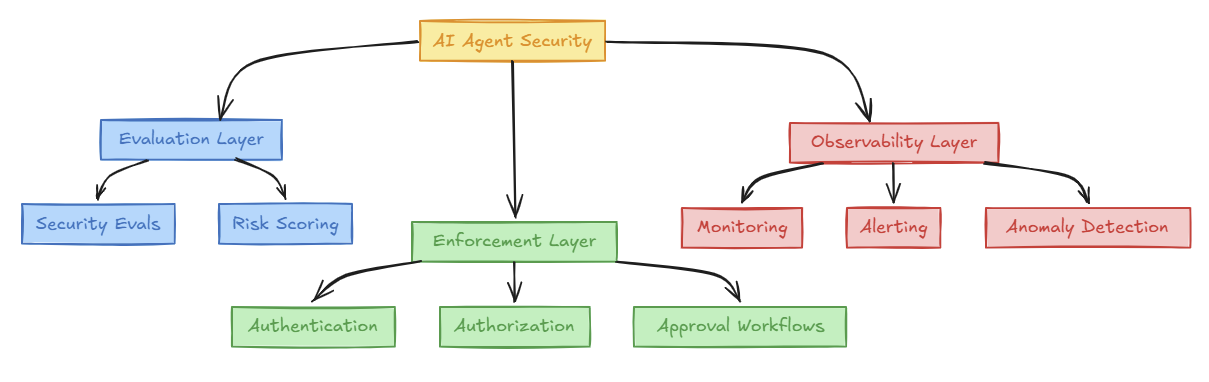
Let's break down each of these layers and understand why they're essential:
Layer 1: Evaluation - Proving Your Agent Is Safe
The first step to security isn't implementation—it's evaluation.
Just as traditional software goes through vulnerability scanning and penetration testing before production, AI agents need rigorous security evaluation.
Here's what a comprehensive evaluation framework should include:
Ground truth testing - Can your agent maintain baseline behaviour when you change prompts, libraries, or LLMs?
Vulnerability scanning - Are your third-party libraries and LLMs free from known vulnerabilities?
Prompt injection testing - Can malicious users hijack your agent through carefully crafted inputs?
Data leakage prevention - Can your agent be tricked into revealing sensitive information?
Unauthorised action testing - Can users manipulate your agent to perform actions they shouldn't have access to?
Runaway agent testing - Does your agent handle edge cases without going into infinite loops or resource exhaustion?
The outcome of these evaluations isn't a simple pass/fail but a comprehensive risk score. This score becomes your decision-making tool for determining whether an agent is ready for production.
This is the future of enterprise AI deployment, whether LinkedIn influencers acknowledge it or not.
Layer 2: Enforcement - Implementing Security Controls
While evaluation tells you how secure your agent could be, enforcement is where you actually implement security controls. And in the world of AI agents, traditional security approaches need significant adaptation.
The primary challenge is identity propagation.
When a user makes a request to an agent, that request may trigger multiple tasks, which in turn call various tools, which ultimately access services or databases. At each step, the user's identity and permissions must be preserved and enforced.
Here's what proper enforcement looks like:
Authentication - Verify who is making the request, whether human or another system
Authorisation - Enforce what the authenticated entity can do based on their role
Identity propagation - Maintain the user's identity context across the entire chain of execution
Least privilege principle - Ensure tools and services use the minimum permissions necessary
Approval workflows - Implement human-in-the-loop or agent-in-the-loop approvals for sensitive actions
A proper security architecture might look something like this:

What's critically important here—and often overlooked—is that authentication doesn't stop at the entry point. Every subsequent action, from task execution to service calls, must verify and enforce permissions based on the original user's identity.
Layer 3: Observability - Monitoring What You Can't Predict
The final layer, and perhaps the most overlooked, is observability. Because AI agents are non-deterministic, you can't test for every possible execution path during development. You need real-time insights into how your agents behave in production.
A robust observability layer should include:
Comprehensive logging - Track every request, response, and decision point
LLM input/output monitoring - Watch what's going into and coming out of your language models
Sensitive data detection - Identify when PII or confidential information might be at risk
Failure rate tracking - Monitor when and why your agent fails to complete tasks
Anomaly detection - Identify unusual patterns that might indicate security issues
Security posture scoring - Maintain a real-time assessment of your agent's security health
The goal isn't just to detect breaches after they happen, but to identify patterns that could lead to security issues before they occur. You can't manually review every request, so you need automated systems that can alert you when metrics exceed acceptable thresholds.
The Paradox of Agent Architecture
There's a fundamental paradox at the heart of agent architecture: the very autonomy that makes agents powerful also makes them potentially dangerous.
Consider the typical AI agent stack:

At each layer, the agent makes decisions about what to do next.
This autonomy is what allows it to solve complex problems—but it's also what creates security challenges. The agent might decide to:
Access data you didn't expect it to need
Call tools in combinations you didn't anticipate
Generate outputs that unintentionally reveal sensitive information
Create execution paths that bypass intended authorisation checks
This is why traditional security approaches often fall short with AI agents. You can't simply define static permission boundaries when the execution path itself is dynamic.
Enterprise-Grade Agent Architecture
So what does a truly secure, enterprise-grade agent architecture look like?
Based on Durai's insights and my own experience, I believe it requires a fundamental rethinking of how we build agent systems.
Here's my proposal for a security-first agent architecture:
Component isolation - Different components (agents, tasks, tools) should run in separate processes or containers with strictly defined interfaces
Dynamic permission boundaries - Access controls that can adapt based on the execution context while still enforcing least privilege
Identity-centric security - A system where user identity and permissions flow through every layer of the stack
Continuous security evaluation - Automated testing that constantly reassesses security posture as the agent evolves
Layered observability - Monitoring that provides visibility from high-level agent behaviour down to individual tool actions
This approach addresses the core challenges of agent security while still preserving the autonomy that makes agents valuable.
The Economics of Secure AI Agents
I've written before about the economics of AI agents, and security adds another dimension to this analysis. Secure agent architecture isn't just a technical requirement—it's an economic necessity.
Consider the cost implications of security breaches:
Direct financial loss
Regulatory penalties
Trust erosion or worse, total loss
Remediation costs
Against these potential losses, the investment in proper security architecture is minimal. Yet many organisations, in their rush to deploy AI agents, treat security as an afterthought rather than a foundational requirement.
This approach is not just technically flawed—it's economically irrational. The ROI on security investment is overwhelmingly positive when you consider the full risk landscape.
Building Your Security Roadmap
If you're developing AI agents for enterprise use, here's a practical roadmap for implementing the Security Trinity:
Phase 1: Evaluation Framework
Define your security evaluation criteria based on your specific risk profile
Implement automated testing for prompt injection, data leakage, and unauthorised actions
Establish a risk scoring methodology that quantifies security posture
Phase 2: Security Controls
Design identity-aware interfaces between agent components
Implement fine-grained access controls at every layer of the stack
Develop approval workflows for high-risk actions
Create isolation boundaries between components
Phase 3: Observability Infrastructure
Deploy comprehensive logging across all agent components
Implement real-time monitoring for security metrics
Develop anomaly detection for agent behaviour
Create alerting systems for potential security issues
Each phase builds on the previous one, creating a progressively more secure agent architecture.
How I’ve Done It: A Security-First Reference Architecture
To move from theory to practice, I want to share insights from my own agent framework Templonix, which implements many of the principles we've discussed.
Templonix is designed as a modular, security-conscious system for rapid agent prototyping that can scale to production.
The architecture demonstrates how to implement the Security Trinity in a real-world system:

This architecture addresses the key security concerns we've discussed and there’s more information in my previous article on AI Agent Guardrails here :
1. Evaluation Layer
Templonix doesn't just implement security—it's designed to make security evaluation testable and measurable through:
Routing policies: All access is controlled through declarative policies that can be audited
Standardised error handling: Errors are captured, structured, and logged for analysis
Rate limiting: Provides protection against resource abuse and helps quantify usage patterns
2. Enforcement Layer
The most critical security principle is the separation of agent invocation from agent execution:
Routing service: Acts as a security gateway, checking if incoming requests are allowed to access specific agents
Agent dispatcher: Dynamically loads agents while enforcing a registry of allowed agent types
Error handler: Provides sandboxing through retry mechanisms and fallbacks
3. Observability Layer
There’s a deliberate use of telemetry across all operations:
Request tracking: Every operation generates a unique request ID that flows through the entire system
Performance monitoring: Timing data is collected for all operations
Structured logging: All components use a consistent logging approach for easier analysis
As a minimum, having the Agent layer separated for an enterprise deployment via a serverless architecture means each agent runs in its own isolated execution environment with tailored permissions. This approach achieves component isolation while maintaining the clean interfaces shown in the diagram.
So What’s the Key Takeaway?
The current discourse around AI agents is dominated by capabilities—what can agents do, how quickly can they do it, how autonomously can they operate. This capabilities race has produced innovations, but it has also created a dangerous blind spot around security.
As we move from pilot projects to production deployments, that blind spot becomes increasingly untenable. Enterprise adoption of AI agents will be gated not by capabilities but by trust, and trust requires security.
Until next time,
Chris