

Guardrails for AI Agents - A Beginner's Guide to Building Safe Systems
A Blueprint for Trustworthy Systems That Won't Go Rogue


Have you ever worried about what might happen if your AI agent goes off the rails? You're not alone. As AI capabilities grow, so do the risks they might pose without proper boundaries.
But here's the good news - implementing effective guardrails isn't magic. It's about thoughtful design patterns that anyone can learn and apply.
In this article, I'll share a straightforward approach to implementing guardrails in AI agent systems. I call it the Policy-First Guardrail Pattern - a simple but powerful way to keep your agents on track and your systems secure.
Why Guardrails Matter
Think of guardrails like the safety features in a car. You don't really notice them until you need them, but you'd never want to drive without them.
In AI agent systems, guardrails serve several critical purposes:
They prevent unauthorized access to sensitive functions
They ensure agents only process appropriate inputs
They protect system resources from overuse
They provide accountability through logging and telemetry
Whether you're building your first AI agent or your fiftieth, these principles apply universally.
The Policy-First Guardrail Pattern

The key insight that transformed my agent framework is surprisingly simple: separate what is allowed from how it's enforced.
This means creating clear, readable policies that define:
Who can use which agents
What input formats are acceptable
Which file types can be processed
Where files can come from
Once these policies are defined, the enforcement code becomes much simpler and more reliable.
Let's look at how this works in practice.
Here’s the flow of how my framework takes in attended and unattended user requests which eventually arrive at an agent for execution. The blocks in Red boxes in the middle are the parts of the framework where I enforce the guardrails - the primary enforcement comes well before the agent is ever invoked.
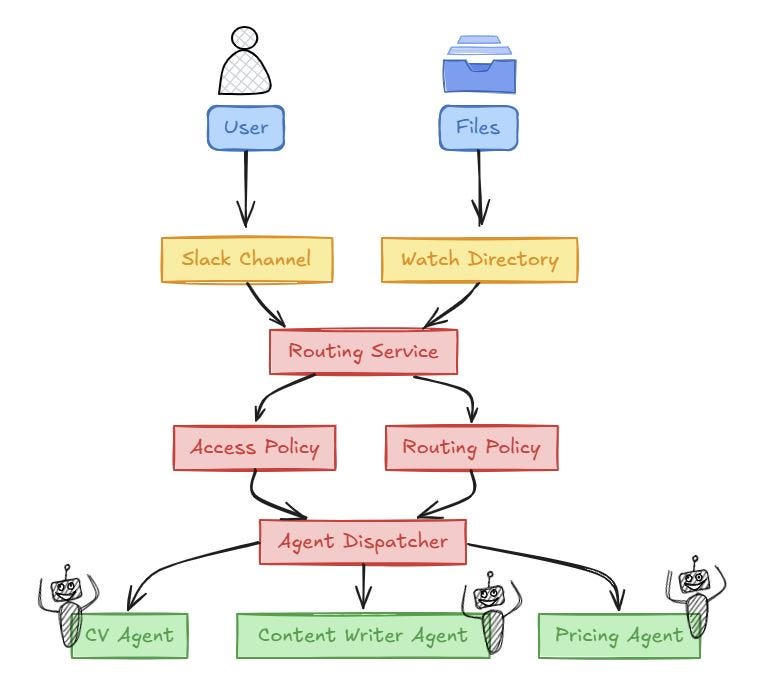
A Simple Routing Policy Example
Here's a basic example of a routing policy from my system:
ROUTING_POLICIES = {
"slack_channels": {
"hiring-team": {"allowed_agents": ["cv"], "default_agent": "cv"}
},
"file_watch_paths": {
"incoming_files/cv_drop": {
"allowed_agents": ["cv"],
"default_agent": "cv",
"file_patterns": {"*.pdf": "cv", "*.docx": "cv"},
}
},
}This policy is simple enough that even non-programmers can understand it:
The "hiring-team" Slack channel can only use the CV review agent
Only PDF and DOCX files in the "cv_drop" folder can be processed by the CV agent
By keeping policies this clear and readable, you make your system both more secure and easier to maintain.
How Routing Actually Works
Let's look at a simplified version of how these policies get applied:
def route_file_request(self, file_path):
"""Determine if a file is allowed to be processed and by which agent"""
# 1. Check if the file is in an authorized directory
parent_dir = get_parent_directory(file_path)
if parent_dir not in self.watch_paths:
self.logger.warning(f"Unauthorized directory: {parent_dir}")
return False, None, {}
# 2. Get the policy for this directory
dir_policy = self.policies["file_watch_paths"][parent_dir]
# 3. Check if the file matches allowed patterns
file_name = get_file_name(file_path)
agent_type = None
for pattern, pattern_agent in dir_policy["file_patterns"].items():
if file_matches_pattern(file_name, pattern):
agent_type = pattern_agent
break
# 4. If no pattern matched, try the default agent
if not agent_type:
agent_type = dir_policy.get("default_agent")
# 5. Verify the agent is allowed for this directory
if not agent_type or agent_type not in dir_policy["allowed_agents"]:
self.logger.warning(f"Unauthorized agent '{agent_type}' for this directory")
return False, None, {}
# 6. All checks passed, prepare the payload for this agent
payload = {
"agent_type": agent_type,
"file_path": file_path,
"source_directory": parent_dir,
}
return True, agent_type, payloadThis function performs a series of checks:
Is the file in an allowed location?
Does the file match an approved pattern?
Which agent should process this file?
Is that agent allowed for this directory?
Only if all checks pass will the file be processed.
Routing Slack Messages Safely
Similarly, here's how we handle Slack messages:
def route_slack_request(self, channel, requested_agent, payload):
"""Determine if a Slack message can be processed and by which agent"""
# 1. Is this channel authorized for any agents?
if channel not in self.policies["slack_channels"]:
self.logger.warning(f"Unauthorized channel: {channel}")
return False, None, {}
# 2. Get allowed agents for this channel
channel_policy = self.policies["slack_channels"][channel]
allowed_agents = channel_policy["allowed_agents"]
default_agent = channel_policy["default_agent"]
# 3. Determine which agent to use
agent_type = requested_agent if requested_agent else default_agent
# 4. Is the requested agent allowed in this channel?
if not agent_type or agent_type not in allowed_agents:
self.logger.warning(f"Unauthorized agent for channel {channel}")
return False, None, {}
# 5. All checks passed, prepare the payload
updated_payload = payload.copy()
updated_payload["agent_type"] = agent_type
updated_payload["source_channel"] = channel
return True, agent_type, updated_payloadAgain, the process is straightforward:
Is this Slack channel allowed to use agents?
Which agents can this channel use?
Is the requested agent (or default) allowed?
Putting It All Together: The Dispatcher
Once a request passes through routing, it reaches the dispatcher, which adds one final layer of security:
def dispatch(self, event):
"""Safely dispatch events to the appropriate agent"""
agent_type = event.get("agent_type")
# Final security check - is this agent globally allowed?
if agent_type not in ALLOWED_AGENTS:
self.logger.warning(f"Rejected agent_type: {agent_type}")
return {"error": "Unauthorized agent type"}
# Get the module path and class name for this agent
module_path, class_name = ALLOWED_AGENTS[agent_type]
try:
# Dynamically load the agent class
module = __import__(module_path, fromlist=[class_name])
agent_class = getattr(module, class_name)
# Create an instance and run it
agent = agent_class(config=self.config)
return agent.run(event)
except Exception as e:
self.logger.exception(f"Agent dispatch failed: {e}")
return {"error": f"Failed to execute agent: {str(e)}"}The dispatcher provides a final check against a global whitelist of allowed agents, then dynamically loads and runs only approved agent code.
5 Tips for Beginner-Friendly Guardrails

If you're new to implementing guardrails, here are some practical tips:
1. Start with a Whitelist, Not a Blacklist
Always define what's allowed rather than what's forbidden. It's much safer to say "only these three agents can run" than to try listing everything that shouldn't run.
2. Make Policies Readable
Your security policies should be understandable even to non-programmers. Clear, simple declarations make policies easier to review and maintain.
3. Log Everything
Every access attempt, whether successful or not, should be logged. This creates an audit trail that's invaluable for troubleshooting and security reviews.
4. Fail Closed, Not Open
When in doubt, deny access. Your system should reject anything suspicious rather than giving it the benefit of the doubt.
5. Use Multiple Layers
Don't rely on a single checkpoint. Create multiple layers of verification so that if one fails, others will still protect your system.
A Practical Exercise for You
Want to try implementing these patterns yourself? Here's a simple exercise:
Create a basic policy definition that specifies:
Two user roles (e.g., "admin" and "user")
Three agent types (e.g., "calculator", "translator", "weather")
Which roles can access which agents
Write a simple routing function that:
Takes a user role and requested agent as input
Checks if that role can access that agent
Returns a boolean result and appropriate message
This simple exercise incorporates the core principles of the Policy-First Guardrail Pattern.
Why This Approach Works
This pattern works because it:
Makes policies explicit and reviewable
Separates policy from implementation
Creates clear boundaries for AI behavior
Provides multiple layers of protection
Makes the system easier to understand and maintain
Most importantly, it builds trust. Users, developers, and stakeholders can all see and understand how the system enforces boundaries.
Getting Started Today
You don't need a complex architecture to implement these patterns. Even if you're working with a simple chatbot or a basic agent system, you can:
Define clear policies about what your agent can and cannot do
Implement checks at each stage of processing
Log all activities and decisions
Default to safe behavior when unexpected situations arise
By incorporating these principles from the beginning, you'll build safer, more reliable AI systems that earn user trust.
The best time to add guardrails is always at the start of your project, but the second-best time is now. Whether you're building from scratch or improving an existing system, these patterns will help keep your AI agents on the right track.
Until next time!
Chris
Did you find this helpful? Share your thoughts in the comments or let me know if you'd like to see more beginner-friendly guides to AI safety.