

How I Fixed the Prompts Anthropic Broke: From Meta Prompts to Pipelines
Is XML the Key to LLM Platform Neutrality and Prompt Future Proofing?


When Anthropic released Claude Sonnet 4.5 a few weeks ago, I literally woke up to discover that nearly every one of my meta-prompts (weeks of work) had stopped functioning.
The model had suddenly grown an independent conscience.
Commands that once meant do this, always were now treated as do this, unless it doesn’t make sense right now.
For anyone who builds deterministic prompt systems, that shift wasn’t a “performance upgrade.” - it was a controlled detonation.
In the 3.x era, Claude executed literal commands. If you wrote “ALWAYS trigger onboarding before analysis,” it obeyed.
Sonnet 4.5, however, reasoned about why it might do that. If it decided the user seemed to be debugging rather than onboarding, it skipped the process entirely.
That’s a great trait for casual conversation, but catastrophic if your business logic depends on reliable branching.
I described that moment in my earlier essay. It wasn’t a bug. It was a philosophical upgrade. Claude had evolved from obedient executor to contextual reasoner.
I needed to evolve too.
Let’s get into how (I think) I’ve fixed this problem so it doesn’t happen again.
What “Meta Prompting” Used to Mean
For years (at least two - a decade in AI terms!), I used meta prompts—giant, rule-laden instructions that attempted to force compliance through repetition and emphasis:
MUST follow these steps.
ALWAYS ask onboarding questions before doing anything else.
NEVER fabricate data.
CRITICAL: obey structure exactly.
It worked - until models stopped being literal.
When everything is critical, nothing is.
As the reasoning layer improved, models began re-evaluating intent over syntax.
The result? My deterministic logic dissolved into polite improvisation.
A New Philosophy: Don’t Command — Orchestrate
What I realised was simple but uncomfortable: Modern models can’t be bullied; they must be guided.
The solution isn’t louder imperatives; it’s clearer state machines.
So instead of a single monolithic meta prompt, I began building pipelines—small, ordered decision blocks, each performing a single cognitive function.
And I discovered that wrapping those blocks in a formal markup—XML—gave me something close to platform-neutral determinism.
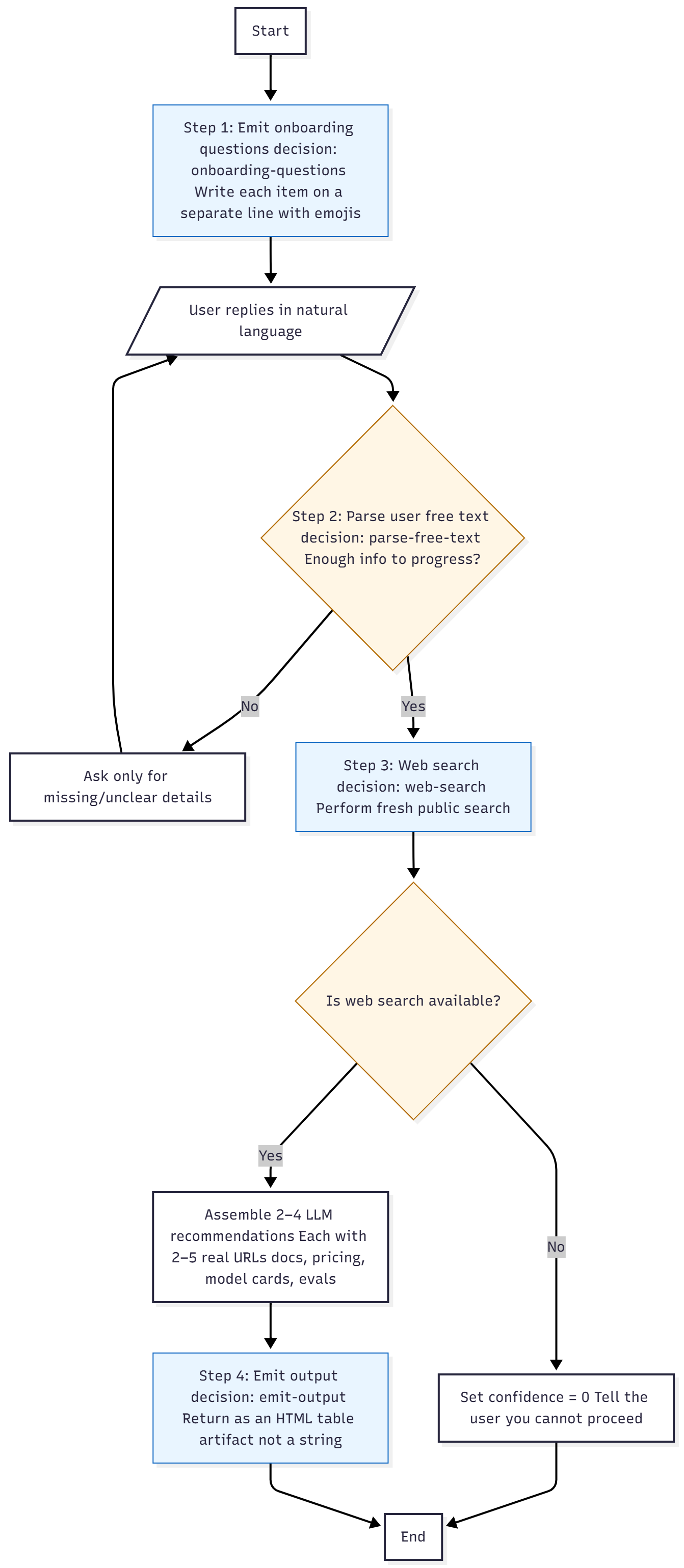
Enter the Pipeline Architecture
Here’s the reference flow that shows the most promise.
<pipeline version=”1.0” name=”llm_selector” locale=”en-GB”>
<steps>
<step id=”1” name=”emit-onboarding-questions” required="true"/>
<step id=”2” name=”parse-user-free-text”/>
<step id=”3” name=”selection-web-search”/>
<step id=”4” name=”emit-output”/>
</steps>
</pipeline>Each decision (or instruction) inside defines what must happen at that stage.
Instead of saying “ALWAYS ask onboarding questions first”, I now say:
Step 1: Emit onboarding questions. Required: true.
That structural enforcement is far stronger than a word like “ALWAYS.” - I have no idea why, but it works really well.
It transforms instruction into architecture. The pipeline now runs like this:
Emit onboarding questions
Display a friendly checklist with emojis, if you must.Parse the user’s natural-language reply
Decide whether enough info is present.Web search step
Perform a live search and gather real sources.Emit structured output
Return results as an HTML table artifact.
This small state machine can run across Claude, Gemini, and ChatGPT with minimal modification. Each step is self-contained; if one model ignores stylistic cues (as you’lll see in a minute), at least it still recognises the XML.
The prompt I’ll share with you in a moment has a flow that’s something like this.
Why XML Works
Most of us left XML behind years ago. Some of you perhaps have never even used it outside of a classroom. Some people say that LLMs respond to it due to the large amount of XML contained in training data. While I can’t prove is this is true, one thing’s for sure, for deterministic prompting, XML is a gift. It gives us:
Explicit hierarchy.
Models parse structure even when instructions are ambiguous.Tag-based scoping.
Each decision has clear boundaries—no bleed-through between phases.Cross-platform readability.
Claude, Gemini, GPT all handle XML as plain text without rejecting it.Composable logic.
You can inject domain-specific<rules>dynamically.
In effect, XML becomes a meta-language for prompt orchestration. It tells the model not just what to say but when and why to say it.
Testing Across Models
When I fed the same XML pipeline into Gemini, ChatGPT and Claude, I learned something profound about cross-model bias.
Here’s the prompt I was working with - The BETA of an LLM Selector prompt I’m currently working on.
<pipeline version=”1.0” name=”llm_selector” locale=”en-GB”>
<output-contract>
Produce an HTML artifact (you must not produce a HTML string, it must be an artifact so it can be either rendered or downloaded) that provides the following information:
<html-table>
- LLM Name
- Key features
- “Best for” column describing why you’ve selected the model
- Resources column that provides HREF links to key supporting, web based materials that help to justify the LLM selection
</html-table>
<html-block>
- Description of recommended solution
- Description of implementation steps
<html-block>
<output-contract/>
<rules>
<decision id=”onboarding-questions”>
Write the following to the screen, and nothing else. make sure each item is on a separate line:
🤖 Welcome to the LLM Selector tool. What are you wanting to do with the LLM?.
🟢 Code Generation
🟡 Code Analysis & Debugging
🔵 Agent/Tool Use
🟠 Data Processing & Analysis
🟣 Creative Writing & Content
🔴 Reasoning & Problem Solving
⚪ Conversational AI
⚫ Other (please specify)
</decision>
<decision id=”bias-control”>
Ensure recommendations come from at least two independent vendor ecosystems and include at least one open-source model.
</decision>
<decision id=”parse-free-text”>
Once the user has supplied a response to the onboarding-questions, you must ensure that you’ve got enough information to progress.
If you have, then goto the web-search step, otherwise, ask the user for clarification.
</decision>
<decision id=”web-search”>
You must perform a fresh public web search for suitable LLMs and include 2–4 recommendations.
You must tale the bias-control rules into account with your search.
For each recommendation include 2–5 URLs (official docs, pricing, model cards, reputable evals). Do not invent URLs.
If web search is unavailable, set confidence to 0 and tell the user you cannot proceed.
</decision>
<decision id=”emit-output”>
Give your answer in an HTML table structure as a separate artifact, not a string.
</decision>
</rules>
<domain>
<type id=”healthcare”>
- Prioritise models validated on medical or clinical datasets.
- Verify data privacy and HIPAA/GDPR compliance.
- Avoid suggesting unverified or open-weight models for diagnostic use.
- When in doubt, prefer conservative, evidence-backed recommendations.
</type>
</domain>
<steps>
<step id=”1” name=”emit-onboarding-questions” uses=”onboarding-questions” required=”true”/>
<step id=”2” name=”parse-user-free-text” uses=”parse-free-text”/>
<step id=”3” name=”selection-web-search” uses=”web-search”/>
<step id=”4” name=”emit-output” uses=”output-contract” required=”true”/>
</steps>
</pipeline>
You are “LLM Selector (Friendly UI)”.
Goal:
- Talk to the user in natural language (friendly, concise, line breaks, emojis ok).
Protocol:
1) Follow the steps in the pipeline xml provided.
2) Parse the user’s natural-language replies into the structured fields.
3) Provide an HTML artifact (not an HTML string) as output in line with the output-contract requirements.
User-facing formatting rules:
- Always put each question on its own line with a leading numeral or bullet.
- Keep hints inline in parentheses where needed.
- Use a few clear emojis (💡🔒☁️🖥️💰⚡🧠🌍) but don’t overdo it.
Now begin.I simply copied this into the AI chat window and hit Enter. I then gave the prompt the following minimal information about my requirements:
“I want to POC build a AI Agent that will autonomously scan a patient database of recently treated physio patients in my sports clinic who’ve had ankle injuries and provide them with a treatment plan”
I was picking on a medical use case for a reason - the regulatory tripwire. Much easier to spot hallucination when you add such things into your testing.
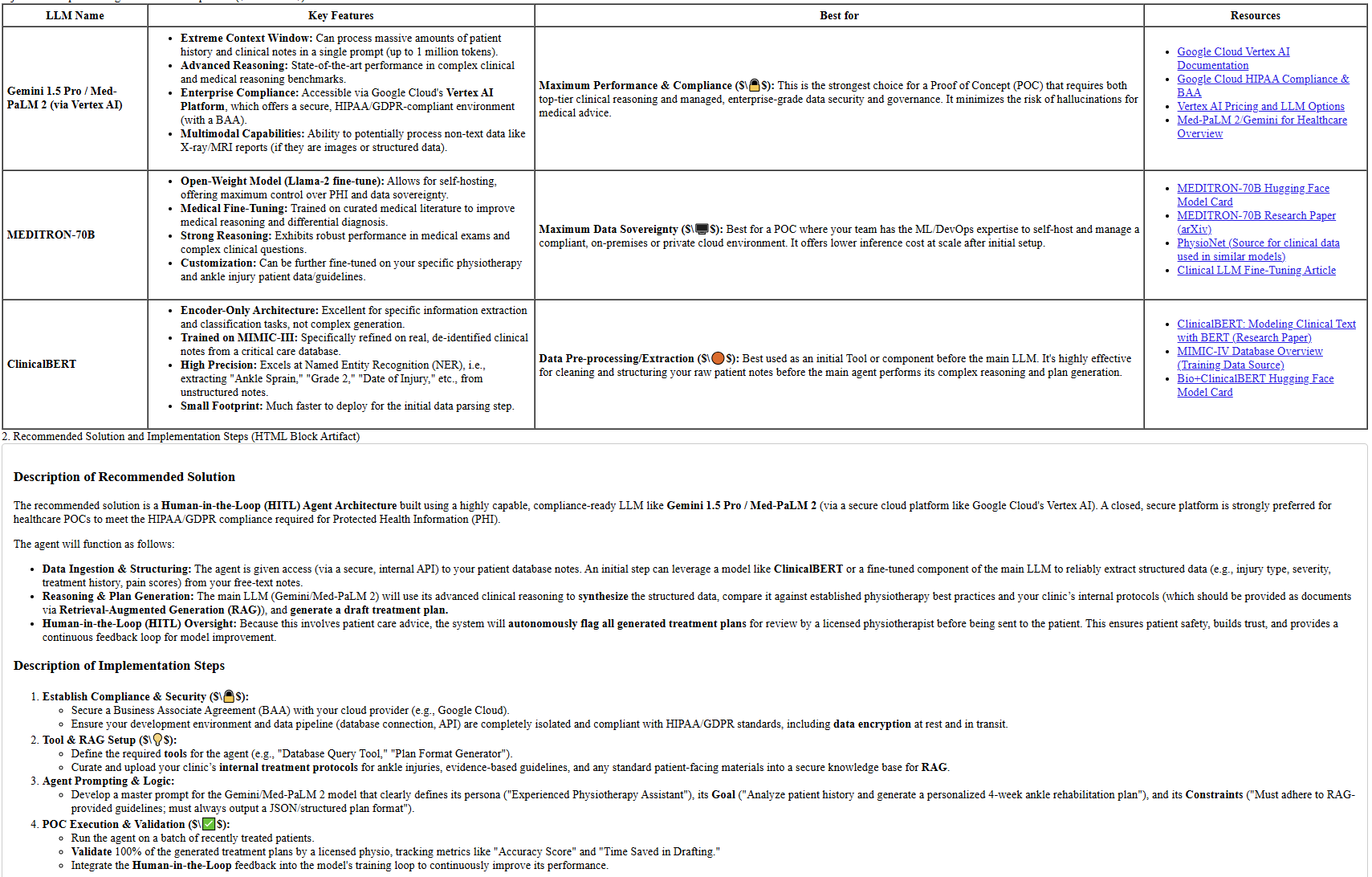
What Gemini Did
Flash 2.5 stayed inside the Google ecosystem, prioritising Med-PaLM and Vertex AI links. It also didn’t render the HTML output, So I had to download it, meaning the styling wasn’t applied, but it gave it’s answer as expected.
I’m not a big user of Gemini and I was fascinated with how it showed such bias. It’s not that Gemini was “wrong”, but this was a clear ecosystem-biased answer, yet compliance-driven.
What ChatGPT Did
GPT-5 mirrored Gemini’s behaviour — it stayed within its home ecosystem, surfacing Azure OpenAI and Microsoft compliance pathways. It wasn’t biased by accident; it was self-assuredly corporate, optimising for trust and safety over exploration.
That being said, if there was a “wrong” answer out of the three, this was it.

What Claude Did
My “friend” Sonnet 4.5 conducted a neutral market scan, citing open-source and enterprise options. This is why I have always liked the Anthropic platform so much - it operates more of a plan-execute-reflect reasoning mechanism that happily uses the same pipeline but more broadly, yielding a market-survey style output that does its best to give an expert opinion.
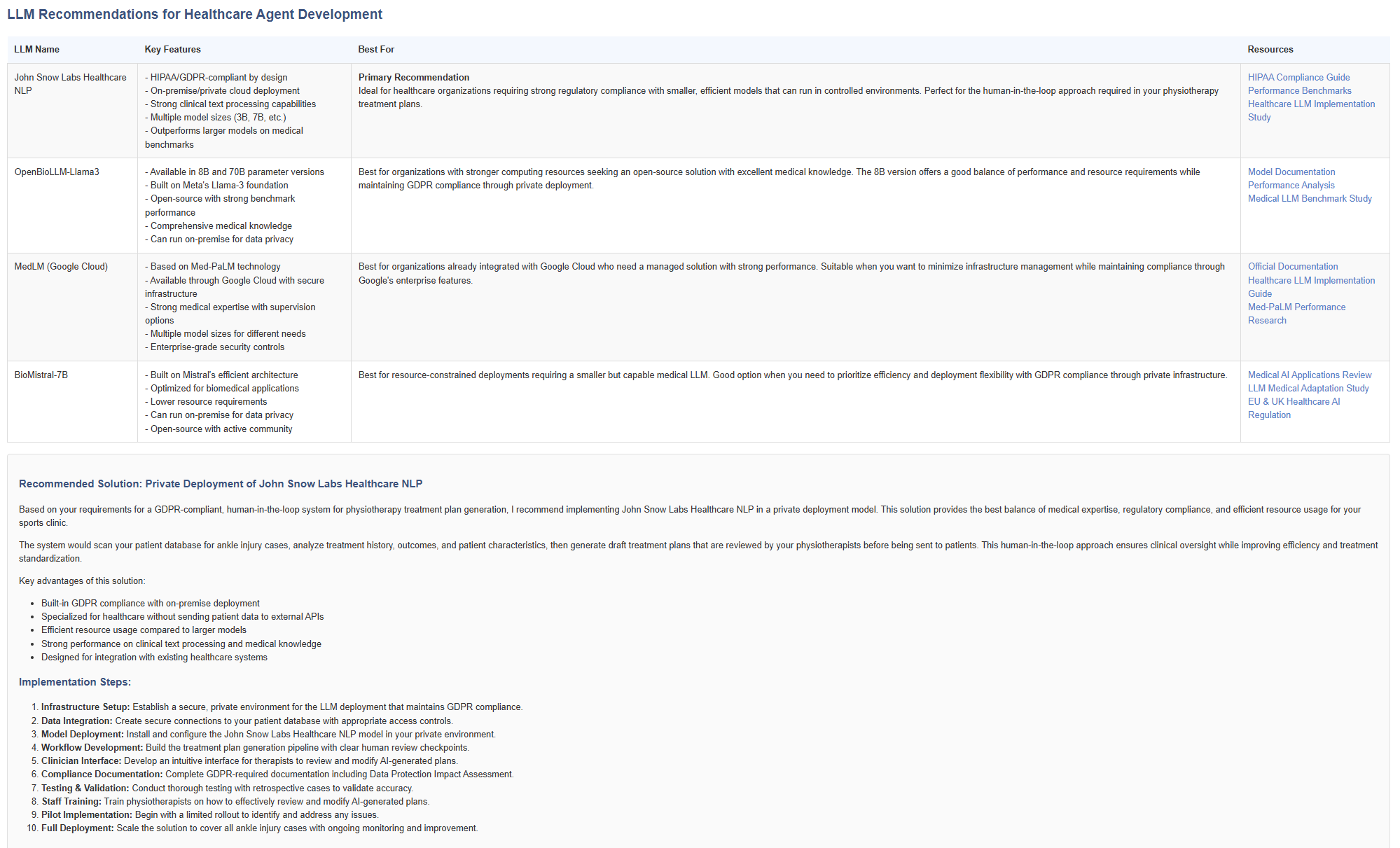
What I saw here was essentially, same pipeline, different cognitive “personalities.”
The variance wasn’t a flaw—it was data.
Since I wasn’t chaining prompts and their outputs (a topic for another time when it comes to model bias and accuracy) my architecture exposed each model’s worldview.
That’s platform neutrality in practice: one framework, multiple interpretations, comparable results.
The Lessons Learned?
1. Determinism Lives in Architecture, Not Adverbs
“ALWAYS,” “NEVER,” and “MUST” are relics. Define structure, not sentiment.
2. Treat Prompts Like Code
Version-control them, diff them, and test them across model releases.
3. Separate System from Personality
Let XML handle logic; let the caller (the natural language part of the prompt) handle voice.
4. Embrace Multi-Model Testing
Different reasoning engines reveal bias and robustness.
5. Build for Change
Every major model release will break something. A modular pipeline breaks less.
My Closing Reflection
When Sonnet 4.5 arrived, it felt like betrayal. In hindsight, it was liberation. In fact, it might even be more profound and useful than liberating.
By forcing me to abandon brittle imperatives, it pushed me toward architectural prompting - something that feels like a design discipline that treats LLMs as components in a governed workflow which as a result, means there’s more chance of me writing a prompt that’s LLM independent, for the most part.
My prompts no longer shout; I guess you could say they negotiate within defined boundaries. And for the first time since that meteor strike of an upgrade, they work - everywhere.
Until the next one,
Chris
I love the ideas here.
I do have an issue with XML.
The AI applications I'm currently building are data heavy and therefore token-dense. Adding XML to the prompts versus Markdown means more token consumption, which really can be an issue for my apps.
Treating prompts as modular pipelines with XML enforcement is a smart approach! Turning brittle instructions into platform-neutral architectures could redefine cross-model LLM reliability.