

The Goldfish with a User Interface
Why most AI agents forget everything — and how to fix it with memory, prompts, and reasoning.


Why am I writing about memory again?
Last week a subscriber was kind enough to leave me the following comment:
Your explanation about memory as a requirement for agents was helpful to this layman. I am a power user of software and AI, but I have been blissfully unaware of the design requirements you discuss. I used Manus.im to create a Python script to convert articles from Reader into text files and download them. I thought that was amazing. Now, I can see that a real agent is far off for me to create by myself. So, my dream of a Tobi Lutke agent team will have to wait.
Reflecting on this (like all good Agents do) I realised that I’d done a pretty rubbish job of explaining why memory is important from a first principles, or bottom up perspective.
Here's the critical insight most people miss: When you chat with ChatGPT, Claude, or any conversational AI, you're not just talking to an LLM — you're talking to an entire system that includes memory management.
The raw LLM underneath (GPT-4, Claude Sonnet, etc.) is completely stateless. It has no idea what you said five seconds ago. But the application wrapped around it maintains your conversation history, manages context, and creates the illusion of continuity.
This is why so many people struggle when they try to build agents. They think: "I'll just call the ChatGPT API and I'm done!" But they quickly discover their "agent" has the memory of a goldfish — forgetting everything between API calls.
So, in an effort to add some more context to last week's newsletter, I'm going to explain, with examples, why Agents that don't have a proper focus on memory management are just Goldfish with a UI.
Let's dive in.
The Problem: Why Most Agents Aren’t Agents
Most tools that claim to be AI agents aren’t really agents at all. They’re just dressed-up pipelines that follow deterministic flows and at some point, use a LLM for some inference. Typically, these flows:
Access some data
Run it through a model like GPT4 with a prompt
Get a response
Move on
No memory. No reflection. No concept of state.
A simple way to visualise this is via a short automation chain in Make.com like this 👇.

If you wanted to take some document data from a MongoDB, process it via the OpenAI LLM and then send it to a CRM system, this automation would have no knowledge of what it had done. Thus, if this was part of an Agent workflow you were trying to build, it means:
The Agent would “forget” past decisions and actions
Can’t learn from mistakes
Can’t track goals across multiple steps
In a business context, that’s a liability. Especially when you’re sending reports, dealing with clients, or maybe even interacting with regulated data.
As I said last week, the point here isn’t to dunk on Make.com or anyone else, it’s just that this is the level at which so many people are building because it’s not understood that the ChatGPT API being used in this flow cannot remember what it’s done because it is stateless.
The Solution: Reason → Act → Remember
While I realise many of you are not programmers, I can at least explain how the memory problem is solved via coding in diagram. It’s actually more of an architecture pattern than anything else, thus making it even more valuable to understand, even if it’s just the concept.
When my Agent “wakes up”, the first thing it does is connect its brain via a bootstrapping process - That’s just a fancy techie term for the Agent being given some things when it starts.
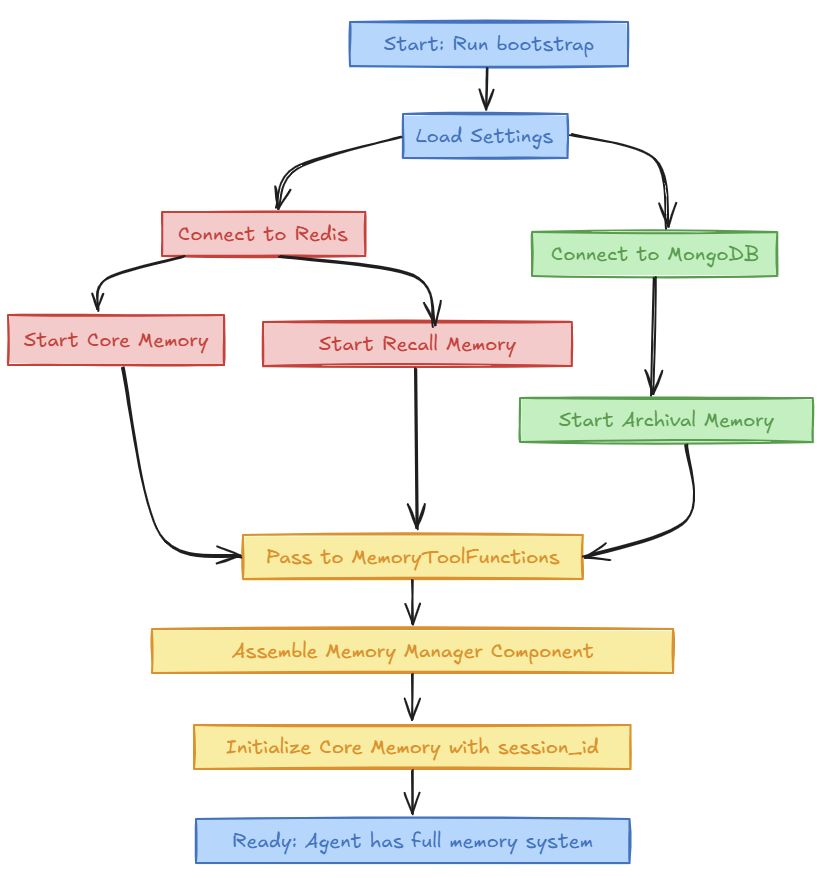
Here’s an simple analogy.
Imagine you’re hiring a new assistant. On day one, they need access to:
A notepad (short-term memory)
Yesterday’s to-do list (recall memory)
An archive of old reports (long-term memory)
But you wouldn’t build all that inside the assistant’s brain. Instead, you’d hand them the tools.
That’s what this diagram shows: when the system starts, it wires up memory by passing it in — not hardcoding it inside.
This is called dependency injection — but here’s a simpler way to think about it:
You don’t give the agent the fruit. You give them a fruit bowl — and let them pick what they need.
By separating what the agent does from where it gets its memory from, the system becomes flexible, testable, and safer to evolve over time.
Once memory is wired in, the agent can:
Reflect on past actions
Avoid repeating steps
Explain why it made decisions
Scale across sessions and workflows
What Happens Next?
Once the Agent’s ready, we can ask it to do something.
Here’s the flow of behavior using the memory architecture the Agent loaded up in its start-up sequence.
I’ve colour coded the boxes above for a reason - the Yellow ones denote steps that are executed in the LLM prompt.
The Green boxes are the more programmatic aspects happening in the code of the Agent once it’s made a decisions about what it needs to do.
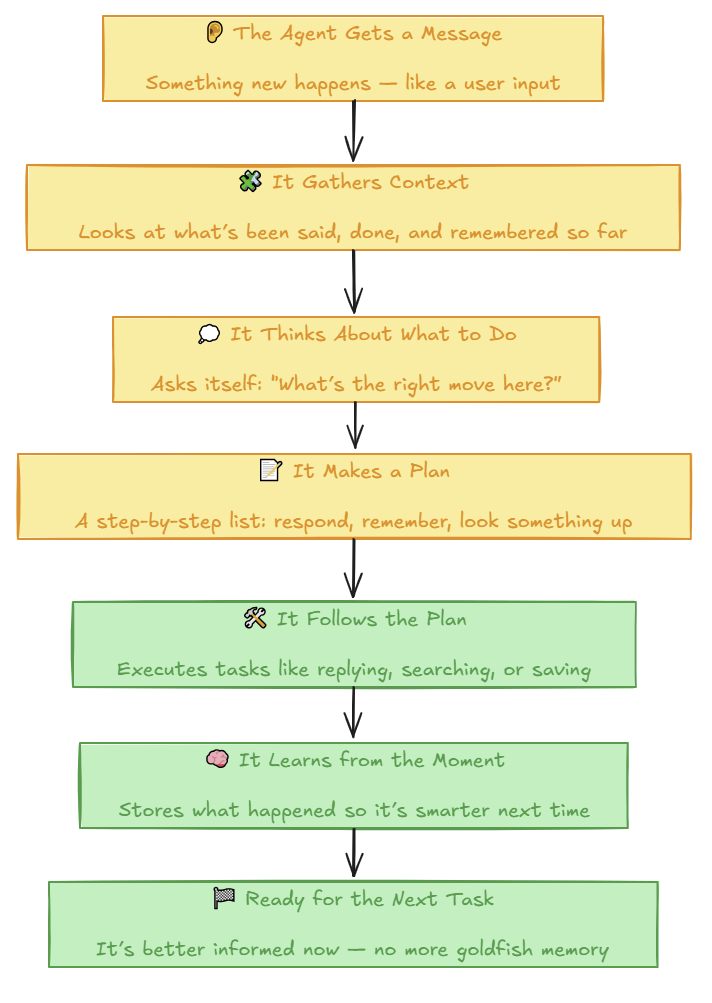
Let’s go in this in more detail.
Prompting the LLM to Decide What to Do
Below is the User Prompt inside my Agent’s primary reasoning function. Note that I do also have a System Prompt that accompanies this when the LLM instruction is executed, but I’m not going to cover this here to keep things simple.
Just to clarify, a system prompt is like the personality and rulebook you give to an AI before it starts talking.
Think of it like hiring an actor to play a role.
You don’t just say “Be helpful.”
You hand them a character brief:
Who they are (e.g., Chris Voss, FBI hostage negotiation genius)
What they believe (e.g., negotiation is about discovery)
How they should speak (e.g., late-night FM DJ tone)
What they must remember (e.g., conversation history, user preferences)
What tools they have (e.g., memory layers, decision rules)
The system prompt sets the stage so every response feels coherent, intentional, and aligned to a role — not just random AI chatter.
Now back to the User Prompt 👇
OK, let’s go through this bit by bit.
CURRENT STATE:
Today's date and time is: {self.date_time}. Your timezone is: {self.locale}
You are not just an assistant — you are a mentor, trained in negotiation strategy, helping the user plan their approach.
Your responses should:
- Coach the user with confidence and insight
- Use strategic framing and risk assessment
- Anticipate pushback and help pre-empt it
- Provide step-by-step negotiation planning
- Use phrases like "I recommend," "Here's how I'd approach it," or "You might want to consider..."The first thing I do is set out the CURRENT STATE. This involves giving the AI the date, time and timezone. Why? Because as we’ve already discussed, the LLM doesn’t know what today’s date is, it’s stateless - remember!
Now I hear you say - “But Chris, that’s not true. If I ask Claude the date, it knows”. Indeed it does.

Why?
Because it’s got a prompt like this one!
Claude.ai the application has a whole host of complex parts that make up the system you interact with.
Claude Sonnet 3.7 the LLM is stateless and thinks the current date is the date it was released after training.
Once we’ve set the CURRENT STATE I give the prompt the data it needs to work with from configuration and memory.
ABOUT YOURSELF:
{persona}
ABOUT THE USER:
{human}
WORKING MEMORY (Current conversation context):
{working_memory}
RECENT CONVERSATION:
{formatted_messages}
CURRENT USER MESSAGE:
{user_input}
MEMORY OPERATIONS PERFORMED SO FAR:
{memory_ops}
{search_results_text}This is the Primary Context the LLM will use when reasoning before it gives a response.
Next, we specify the steps we want the LLM to take. This is where the Agent essentially makes a plan of what to do and decide the actions it needs to take. As you can see, there are rules and limitations as to what it can and cannot do.
Think step-by-step about what memory operations or response are needed next.
You have the following actions available:
1. "search_recall" - Search conversation history for relevant information
2. "update_core" - Update core memory with important new information
3. "search_archival" - Search long-term archival memory
4. "store_archival" - Store detailed information in long-term memory for future reference
5. "respond" - Generate a final response to the user
6. "create_document" - Build a Word document (based on current task/memory context) and email it to the user
This action uses recall and core memory as these are the areas of the memory architecture that contains the data needed to build a structured document and sends it as an attachment.
Examples include:
- “Can you write this up and email it to me?”
- “Send me the report”
- “Email me what you’ve got so far”
- “Wrap this into a Word file and send it over”
IMPORTANT: When using "update_core" or "store_archival", the "content" field MUST be a string, not a dictionary or object.
For example: content: "Current topic: birthday planning. Event date: Saturday"Once the Agent has decided what actions it’ll, the final stage is to build and return a Response Object in a JSON (JavaScript Object Notation) format.
Select a main action and any necessary follow-up actions:
Return a JSON object with the following structure:
{{
"main_action": {{
"action_type": "action_name", // One of the actions listed above
... (action-specific fields) ...,
"reasoning": "Why you're taking this action"
}},
"follow_up_actions": [
{{
"action_type": "action_name",
... (action-specific fields) ...,
"reasoning": "Why you're taking this follow-up action"
}},
// Additional follow-up actions if needed
]
}}
Action-specific fields:
- For "respond": "response_content": "Your response here"
- For "search_recall": "search_term": "term to search"
- For "update_core": "memory_block": "persona|human|working_memory", "content": "Content as a STRING"
- For "search_archival": "search_term": "term to search"
- For "store_archival": "content": "Content to store as a STRING"
- For "create_document": No additional fields required
REMEMBER: If you provide a detailed response (like a recipe), you MUST include a "store_archival" follow-up action. Now here’s the crucial part: once the AI has figured out what it wants to do… it doesn’t just reply. It builds a plan — and it writes it down in a format called JSON.
Think of JSON like a checklist on a whiteboard. It’s the agent saying:
“Here’s what I’m about to do, why I’m doing it, and what I’ll need to follow up on.”
Each line in the checklist maps to a tool the agent can use — like:
Look something up in memory
Update a detail about the user
Create a document
Send an email
Just reply and be done
What Happens After the Plan Is Made?
Once the Agent finishes “thinking,” it returns a plan written in JSON — like a to-do list for itself.
But now it has to do the work. Here’s what happens next:
✅ 1. It Follows the Plan
The Agent looks at the plan and carries out the steps:
If the plan says search memory, it runs a memory query.
If it says update user info, it edits its core memory.
If it says create a document, it fires up the document builder.
Each step is handled by a real tool — bits of code built to do specific jobs.
Think of the LLM as the “strategist” and the tools as the “hands.”
🧠 2. It Learns from the Moment
When the task is done — especially if it’s important (like sending a document or handling a negotiation strategy) — the Agent logs what just happened.
It writes the outcome into long-term memory, so next time, it can:
Avoid repeating work
Reference what was already said
Build better responses
This is how the Agent gets smarter over time.
🚦 3. It Waits for the Next Task — Now Better Informed
Once the work is done, it pauses and waits — ready to repeat the process the next time you message it.
Only this time, it’s carrying a little more wisdom than before.
No more goldfish memory. No more starting from scratch.
Just real reasoning, structured action, and memory that compounds.
How This Works in Practice
Let's walk through what happens when we use the Sales Agent I introduced in last week’s original newsletter.
What’s the agentic flow when we ask him: "What's our strategy for the ACME renewal?"
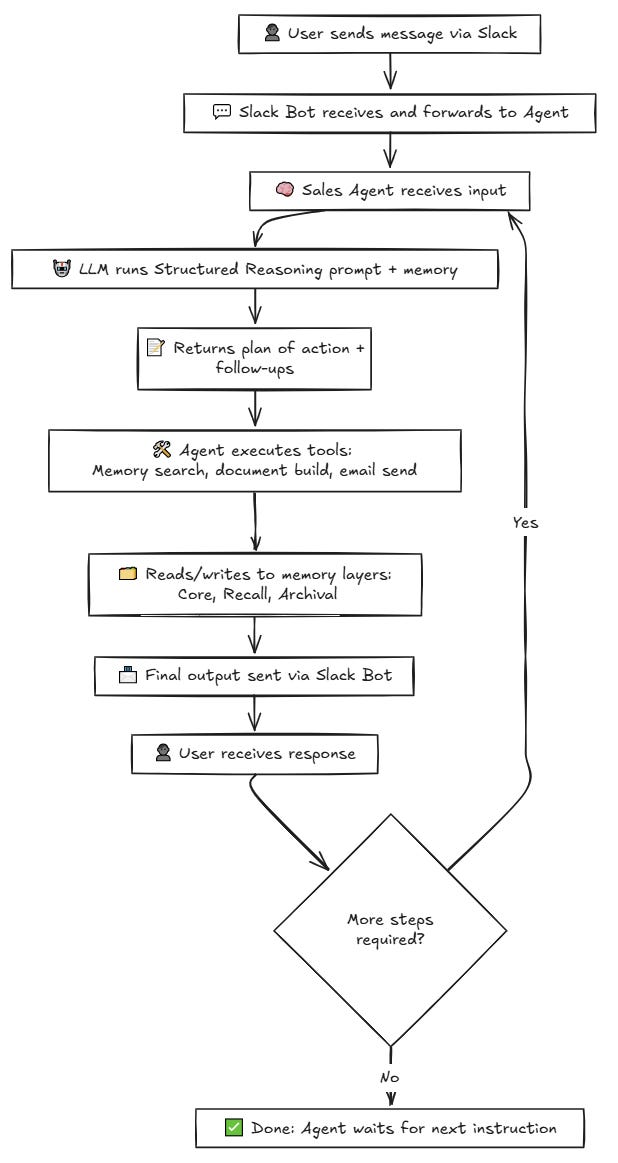
Step 1: The Agent Wakes Up and Gathers Context
When you send this message, the agent doesn't start cold. It immediately pulls together everything it knows:
Core Memory: "I am a strategic sales consultant specializing in contract renewals"
Recall Memory: Recent conversations about ACME's pricing concerns
Working Memory: Current conversation context
Step 2: The Agent Reasons About What To Do
The agent thinks: "The user mentioned ACME - that's a client name. I should trigger my renewal workflow." This happens through the _should_trigger_workflow function in the code:
Step 3: The Workflow Kicks In
Now the agent follows a structured plan:
Load CRM notes that contain information about quarterly customer reviews
Pull the current contract details
Search the Web - It runs targeted searches for recent ACME news
Analyse Sentiment - It evaluates the overall health of the relationship
Generate Report - It creates a comprehensive renewal strategy
Each step uses real tools - file readers, web scrapers, LLM calls - orchestrated by the agent's decision-making.
Step 4: The Agent Updates Its Memory
After generating the report, the agent doesn't just return it and forget. It:
Stores the complete report in archival memory
Updates working memory with key insights
Logs the action in recall memory
This is the crucial difference from simple automation. The agent knows it created this report and can reference it later.
Step 5: Handling Follow-up Questions
When you ask "Why did we rate the renewal 8/10?", the agent doesn't need to regenerate everything. It:
Searches its memory for the report
Finds the scoring reasoning
Explains the specific factors that led to that score
The Magic: Continuity Through Memory
Without the three-tier memory system, the agent would be lost. It wouldn't know:
That it just created a report
What factors went into the rating
How this relates to previous ACME discussions
But with memory, it maintains context like a human colleague would. Each interaction builds on the last, creating a coherent experience rather than isolated transactions.
This is why your agent can handle complex, multi-turn conversations about negotiations, reference past strategies, and evolve its approach based on what it learns - not just respond to individual queries in isolation.
The sequence diagram shows this technically, but the lived experience is seamless: you're talking to an assistant that actually remembers and learns, not a goldfish that forgets everything after each response.
Wrapping Up: Why This Matters More Than You Might Think
By now, you’ve seen that real AI agents aren’t just clever chatbots. They think, act, and remember — like a junior teammate with a brain wired for learning.
Here’s what separates the toy projects from the real thing:
Memory, so the agent doesn’t repeat itself
Reasoning, so it plans before it acts
Tools, so it can actually get things done
JSON, so it can explain what it’s doing, and why
And the kicker? This isn’t some abstract design theory.
This is exactly how the SalesAgent I built works — being tested by users today, generating Word documents, talking to users, and evolving through experience.
What You Can Take From This (Even If You’re Not Building Yet)
If you’re learning AI, or hoping to land a job in this space, this is the kind of thinking that stands out. Not just “Can you prompt ChatGPT?” But:
Can you describe how agents think?
Can you talk about memory, state, and actions?
Can you break down architecture like this for someone else?
You don’t need to build a full agent to benefit from this. You just need to understand what makes one real.
One Final Thought
If you’ve ever built a Make.com workflow or a Zapier chain — great. You’re halfway there. Now imagine giving that automation a brain.
That’s what memory does.
That’s what reasoning does.
That’s what architecture does.
And if you can explain this to someone else… You’ve already started your pivot from user → builder.
Until the next one, Chris.
🧰 Ready to Go Deeper?
The Agent Architect’s Toolkit is my full library of premium agent design patterns, prompts, scorecards, and case studies, built from real enterprise deployments.
If you’re serious about designing or deploying agents in production, this is where you start.
Very glad to have come across these notes. For quite some time now I had been actively attempting several different methods to overcome the very same problem. The closest to my need has so far been the 'capsule' approach. Quick explanation would be definite repititive systematic encryption to reduce text volume down to less than 10% at every instances when the cumulative conversation history has crossed some specific threshold, say 10 million characters total (including the capsule of N-1th round) and then automatically erasing the long version for every iteration and print the capsule in the core memory, not overwriting the older capsules though, very important to call that out, for itself to have a reference point of cross validation, whether the decryption was accurate.
Let me know what you think of this approach.