

The Memory Illusion: No-Code Agents vs. Production Reality
What n8n, Make.com, and YouTube "Experts" Won't Tell You About True Agentic AI


Everyone is being lied to about AI agents.
You see it everywhere — slick videos showcasing no-code "agents" performing impressive feats using drag-and-drop interfaces. A CTO on Reddit claims n8n is working miracles for workflows. The YouTube algorithm bombards you with creators promising "build an agent in 10 minutes with zero code."
The truth? These aren't agents.
They're automations masquerading as intelligence.
True agentic AI isn't about stringing together a series of predefined API calls in a visual editor. It requires something far more fundamental:
Robust memory management.
A Memory Crisis is Emerging…
Over the past several months, I've been building semi production-grade AI agents for my clients as part of what we do at Templonix.
Semi-production you might ask?
Working prototypes built to allow clients see the technical and financial operations of an agent within their walled garden before they make a serious decision to invest on what is (let’s face it) an embryonic technology from a business perspective.
It’s also the right approach to take. Why? Because despite what YouTube might say, agents are not built in a day!
Anyway, I digress…
In all of the coding I’ve done in the last six weeks, the consistent bottleneck wasn't the LLM, the accessibility of data, formats of data or the business requirements; it was the memory architecture.
The fundamental problem is simple but profound: Large Language Models are stateless by design.
As Charles Packer, lead researcher on MemGPT at Berkeley explains:
LLMs effectively have no memory. They just have the memory that's in their weights and then they have what's in the context window.
In other words, these powerful models can reason but can't remember.
I cannot overstate this enough.
I think there is a massive discrepancy with what people actually know about this.
This creates a critical limitation for any system expected to maintain coherence over time.
Without proper memory management, even the most sophisticated agent will eventually:
Forget critical information shared by users
Contradict its previous statements
Fail to retain learning or evolve with experience
Collapse under token limits during complex workflows
The consequences in production environments are severe. Imagine an AI agent that assists with customer support suddenly forgetting a user mentioned they'd already tried the standard troubleshooting steps. Or a document analysis agent that loses track of key information when scanning lengthy contracts.
No amount of graphical interface polish can solve this architectural problem.
The Three-Tier Memory Model (Inspired by MemGPT)
To solve this, we must think like operating systems do. That means constructing a memory hierarchy that allows the LLM to page relevant data in and out of its limited working memory.
This is where the three-tier architecture comes in.
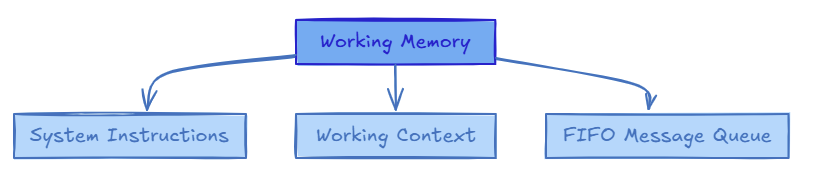
1. Working Memory (Main Context)
This is the LLM's active context window — a few thousand tokens of live, in-the-moment memory. It includes:
System instructions
The working context (facts and task-related state)
A FIFO queue of the most recent messages
Think of it like the RAM of your AI system.
The LLM can only attend to what fits here. If it falls out of context, it might as well be forgotten. But this memory is incredibly fast and always available during inference.
2. Recall Memory (Short-Term Disk)
This stores previous interactions, structured notes, or ephemeral details from the current session. It's searchable and can be brought back into working memory on demand.
Examples include:
Past user queries and assistant replies
Notes captured during reasoning
Ephemeral state that doesn't belong in the core system persona
It's analogous to paging in and out of disk. Not everything fits in RAM, so you store what matters and bring it back when needed.
3. Archival Memory (Long-Term Store)
This is your deep memory. Key documents, CRM logs, contract data, event histories — all structured and stored persistently across sessions. Often backed by a vector store or database.
Agents can:
Store finalised reports and outcomes
Search using embeddings or keyword indexing
Access structured datasets like JSON blocks or vector graphs
This is your equivalent of an SSD or database. It's slow to query relative to RAM but enables reasoning over months or years of data.

Why This Matters in Practice: A Real Agent in Action
The latest project I’m working on is a Sales Agent designed for contract renewal support — and it embodies this memory architecture in a very intentional way.
Here’s how it works:
The agent begins in conversation mode, responding naturally to a salesperson’s prompt like “What’s the status of the ACME account?”
Behind the scenes, it searches recall and core memory to provide context-aware responses. Nothing feels rigid or scripted.
But then something crucial happens.
When the agent detects that the user has mentioned a known client — thanks to intent detection and a structured system prompt — it tips out of conversation mode and into workflow mode.
This is a hard shift, guided by the agent’s own job description:
Conduct CRM analysis
Parse contract terms
Run a web search for current news
Perform sentiment scoring
Generate a negotiation strategy report
Once the workflow completes, the agent produces a multi-section Slack-ready strategy doc and stores it into archival memory.
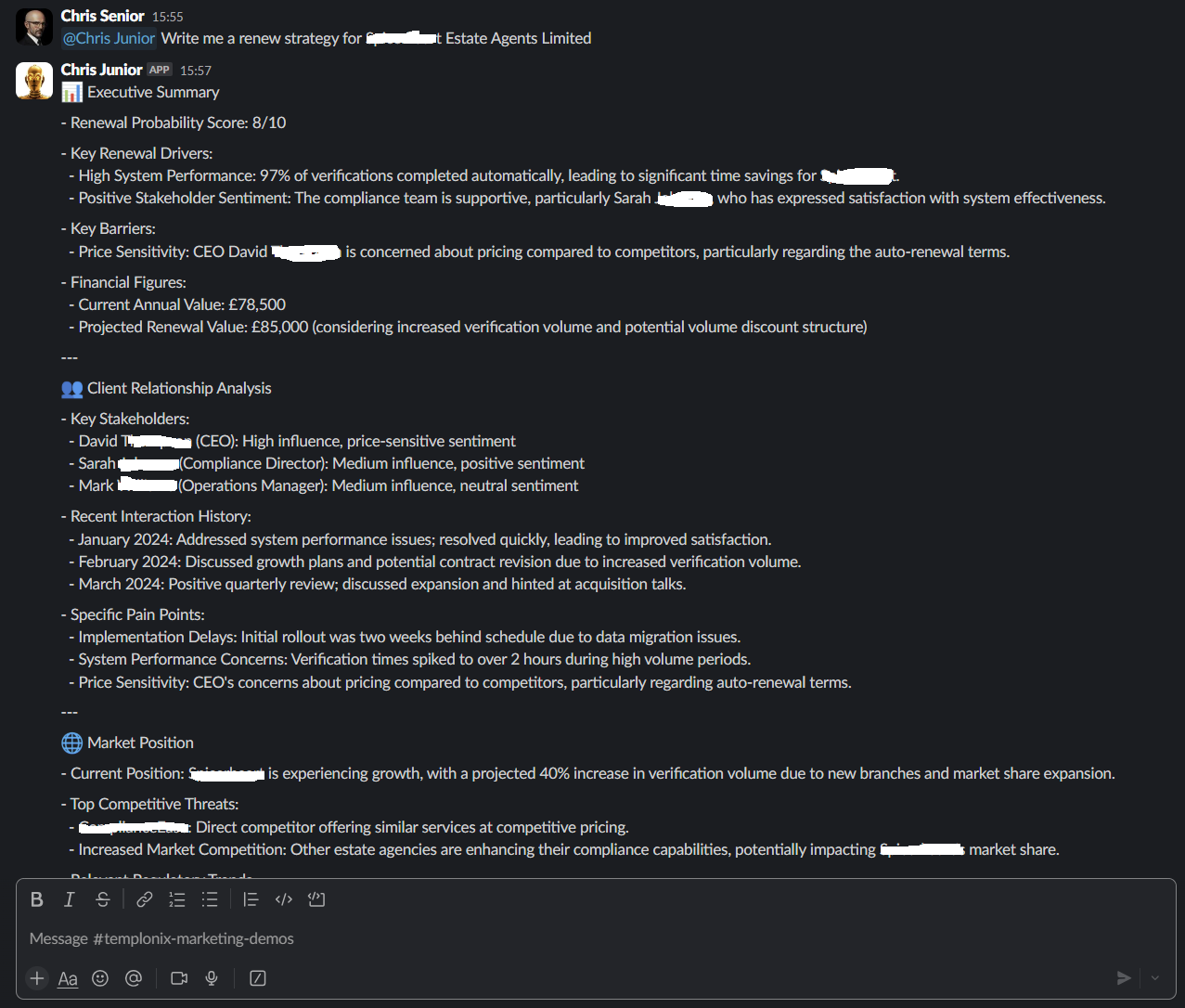
And here's the magic: when the salesperson follows up with a question like, “Why did we rate the renewal 8/10?” — the agent seamlessly continues the discussion.
Because it has memory.
It remembers the report.
It understands its own output.
And it can explain and extend the logic without needing to rerun the entire workflow.
This isn’t prompt hacking. It’s architectural discipline.
No-Code UIs Won’t Save You
There’s a dangerous myth gaining ground: that AI agents can be built in a few clicks using no-code tools. While these platforms are useful for simple task automation, they collapse when faced with the complexity of true agentic reasoning.
Why? Because they fundamentally misunderstand — or ignore — the role of memory.
Most no-code systems rely on crude workarounds. They concatenate everything into one giant prompt and hope the LLM can sort it out. Or they rely on ephemeral in-session state that disappears as soon as the workflow resets. Others may offer vector search as a bolt-on feature but treat it like a clipboard, not a structured memory system. What they cannot do is distinguish between temporary knowledge, essential working context, and long-term understanding — because they lack the architectural layers to do so.
In practice, these systems can’t sustain coherent dialogue, can’t reason over evolving information, and can’t adapt to complex, multistep decision processes. They might look functional in a demo. But they degrade quickly when the edge cases arrive — and they always arrive.
If you're not managing memory with the care of a systems architect, you're not building an agent. You're stitching together a brittle, shallow facade of one.
So What’s the Takeaway?
This isn’t about dunking on no-code. It’s about recognising that as soon as you ask an AI system to do more than respond — as soon as you expect it to track, remember, reason, and act — you’re entering the realm of real software architecture.
Memory isn’t an optional feature you sprinkle on top. It’s the operational backbone of any credible agent system. And just as operating systems evolved from linear programs to multitasking kernels with layered memory hierarchies, so too must our agents.
At Templonix, this has become a non-negotiable design principle. We don’t prototype agents without a memory plan, because we’ve seen what happens when you do. The illusion works — for a while. Until the moment your agent forgets what it just said, contradicts itself, or fails to recognise something it produced two minutes earlier.
We build memory-first because it’s the only way to build agents that hold up to real-world demands. And if you’re serious about deploying AI systems that last longer than a demo, so should you.
Until next time!
Chris
Did you find this helpful? Share your thoughts in the comments or let me know if you'd like to see more beginner-friendly guides to AI Agent development.
Your explanation about memory as a requirement for agents was helpful to this layman. I am a power user of software and AI, but I have been blissfully unaware of the design requirements you discuss. I used Manus.im to create a Python script to convert articles from Reader into text files and download them. I thought that was amazing. Now, I can see that a real agent is far off for me to create by myself. So, my dream of a Tobi Lutke agent team will have to wait.