

Reflection Pattern Codswallop
Don't Believe Everything you Read on LinkedIn


Refining repetitive tasks in AI Agent workflows doesn’t always require explicit Reflection prompts.
In my experience, when you’re effective in using memory systems and passing contextual parameters, Large Language Models (LLMs) demonstrate an impressive ability to iterate and improve on their own.
This is a massive departure from the sh**posting on LinkedIn on the topic. At times, it’s quite embarrassing to see. What I want to get across to you is this - just let the machine do the work. It’s smarter than you and me!
What You’ll Learn Today
When building AI-powered systems, one of the most enticing promises is their ability to improve over time. Developers often assume that explicit programming - such as reflection prompts or dedicated fine-tuning, is need for meaningful refinement.
My experience with an AI Agent-based system has shown otherwise.
Today I’ll walk you through how an update I’ve been working on to my framework (using the gpt-4o model) achieved a champion level of improvement - a 15-20% enhancement in output quality, to be precise - without requiring explicit Reflection prompts.
Instead, it leveraged vector memory, task decomposition, and thoughtful parameter passing.
By the end of this article, you'll see why this shift in approach could be game-changing for developers and organisations alike.
1. Understanding the Workflow
Before diving into the specifics, here’s the basics of what my Agent workflow is doing that involves Reflection.
Goal Definition
The system is tasked with high-level objectives, such as researching AI trends or generating predictions. Goals are the root activities, defined with a broad statement of requirements.
Task Decomposition
The Agent then breaks down goals into smaller tasks. For example, a goal might translate into web searches (one or more) followed by synthesising the results into a summary.
Execution Loop
The system repeats this process at regular intervals, leveraging stored outputs and learnings.
Memory Utilisation
Results from previous executions are stored in a vector database and retrieved for context in subsequent runs.
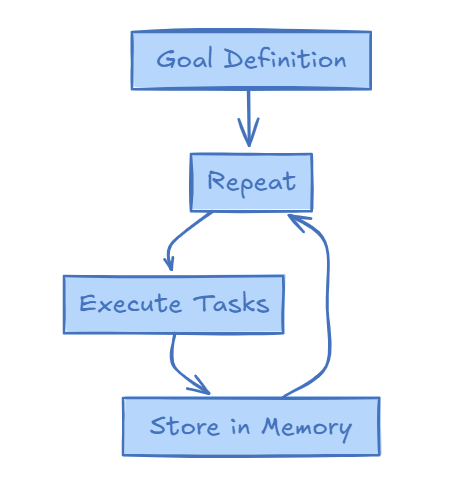
Despite the apparent complexity, the key here is simplicity - rather than explicitly asking the LLM to “reflect” on prior outputs, the agent uses context from memory, enabling the model to reason naturally.
2. Reflection Without Reflection Prompts
Traditional thinking might suggest that to achieve refinement, you need to explicitly program reflection into the AI’s workflow. For example, you might write prompts asking the system to analyse prior results, extract lessons, or directly reference past outputs.
Here’s the surprising truth: it’s often unnecessary.
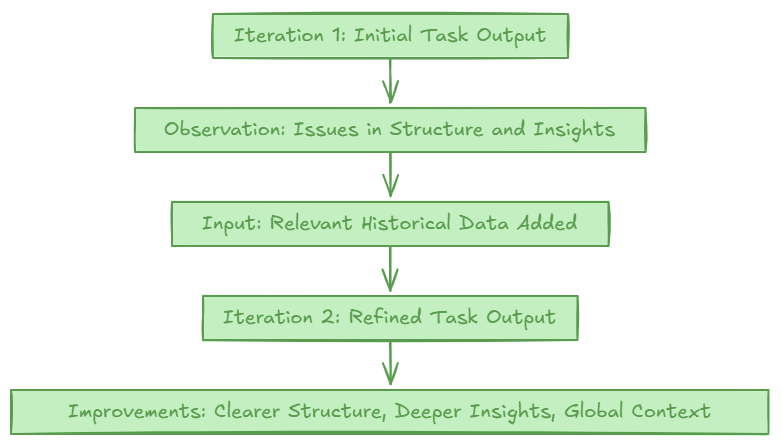
In one experiment, I tasked the system with generating three iterations of an article about Bitcoin’s 2025 price predictions. The second iteration showed:
Better structure and clarity.
Deeper insights, including more nuanced discussions of global market dynamics.
Clear evidence of incorporating prior outputs’ conclusions.
I gave the output to ChatGPT to give an opinion. Here’s what it thought.

And yet, no Reflection-specific prompts were involved. Instead, the LLM naturally integrated past context when fed with:
Relevant prior results retrieved from a vector store.
Parameters guiding the task (e.g., "Use previous sources to enhance clarity").
Key points to remember: When given enough relevant context, LLMs can reason about prior data effectively on their own. Think of it like chatting with a friend who remembers the last conversation without needing explicit reminders - natural, seamless, and efficient.
3. The Role of Memory Systems
The real super-hero of this process is the memory system.
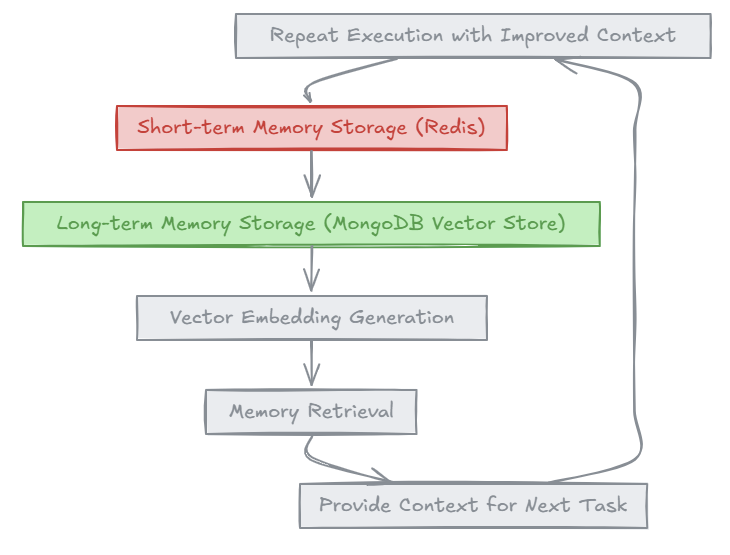
In my setup, I use:
Short-term memory: Redis for managing active tasks and recent results.
Long-term memory: A MongoDB vector store to archive embeddings of past goals and their outcomes.
When the Agent begins a task, it retrieves similar past goals, enabling the LLM to “read the room” before diving in. This retrieval process provides:
Historical context - Relevant patterns or conclusions from past tasks.
Enhanced consistency - Ensures outputs align with prior work.
Improved reasoning - The LLM connects dots naturally, without explicit instructions.
What makes this elegant is that the memory system doesn’t dictate how the LLM reasons. Instead, it acts as a knowledge base, leaving the model to determine how best to use the information.
The result? Refinement emerges organically.
Your AI agent doesn’t need a lecture on reflection—just give it a good memory and watch it thrive.
4. Implications for Business Applications
This approach isn’t just a technical novelty - it’s a blueprint for real-world Agentic systems.
Consider a customer service bot deployed by a telecom company. Instead of manually tuning responses to recurring queries, the Agent can:
Leverage prior interactions (stored as embeddings) to refine its tone and accuracy.
Avoid redundancies by recognising patterns from past cases.
Provide faster, more relevant answers, leading to improved customer satisfaction.
This makes Agentic systems:
Easier to build and maintain - No need for complex reprogramming.
Cost-efficient - Eliminates the overhead of fine-tuning for every scenario.
Scalable - The Agent learns and improves autonomously, keeping pace with growing datasets.
5. Practical Tips for Developers
To replicate this success in your own projects, keep these tips in mind:
Invest in Memory Systems
A robust memory architecture is critical. Tools like Redis and MongoDB (or vector stores like Pinecone) make this achievable.
Pass Context Thoughtfully
Ensure task prompts include relevant historical data without overwhelming the LLM.
Test Iterative Improvements
Analyse outputs across iterations to validate refinement and identify bottlenecks.
Avoid Overcomplication
Skip unnecessary reflection prompts unless your use case demands explicit meta-analysis.
Monitor Performance
Continuously evaluate the system’s outputs to ensure alignment with business goals.
In AI development, simplicity often wins - let the system’s architecture do the heavy lifting.
Key Takeaways
As always, let’s consider the learning with this.
✅ Skip Reflection Prompts. LLMs reason effectively when given contextual memory - there’s really no need for extra programming for the vast majority of use cases that need Reflection.
✅ Memory Matters. A well-designed memory system allows AI Agents to integrate historical data naturally. As I said, I use Redis and Mongo Atlas (document stores and a vector store) in Templonix.
✅ Business Benefits. This approach reduces overhead, improves scalability, and streamlines AI deployment. Nowt bad about that eh?!
✅ Simplicity Wins. Focus on clear parameters and robust infrastructure to achieve continuous refinement. Again, the models are smarter than you think.
If you’re using AI agents or planning to do so, I'd love to hear about your experiences and challenges.
Drop a comment below or reach out directly—I read every response.
Cheers for now,
Chris