



How to Build an AI Agent You Can Trust
Why an Agent Isn't an Agent Without a Graph


Building an Agent you can trust is no mean feat. How can you have confidence in an AI response when we all know hallucination is rife within LLM architecture. While these new tools and technology appear intelligent, it’s exactly that - the majority of the time it’s just appearance.
That being said, quietly, behind the noise and hype, a real pattern is emerging.
This pattern isn’t coming from influencers. It’s coming from the teams actually shipping production agents — at Bloomberg, Ramp, OpenAI, and a handful of startups (cough, cough) doing the hard work of integrating Agents into live business processes.
And the thing is — many of us are converging on the same structure, even if we’re building in different domains.
What is this pattern I speak of? I call it the Repeatable Expertise Pattern.
It’s the basis of a new project I’m working on - a resume screener for a recruitment consultancy — one that replaces 10 recruiter hours with an Agentic solution that can do better than a human in 7-minutes. But more importantly, it’s a design that shows up again and again in systems that are doing real work, not just demos.
Let’s unpack it. Oh, and there’s some code with this one, so you can try this out for yourself if you like. 👇
The Repeatable Expertise Pattern
As I explained in Part 5 of the anatomy series, Agent Economics offers businesses a choice; replace the humans or augment them and scale to new heights of profitability. What executives decide to do is up to them, the trick is to understand what they want (or need) to augment or replace and the answer is, it’s Repeatable Expertise.
Think about it: How many processes in a digital workflow don’t involve the need for some kind of judgement? I’d say none.
Why? Because most business tasks aren’t just about “getting information”, they’re about making decisions — hiring the right person, approving a supplier, investigating a compliance issue. That means:
Gathering information from different sources
Asking questions to clarify what's important
Connecting the dots across domains
And ultimately, making a call that stands up to scrutiny
This is human reasoning. And it hinges on one critical skill: understanding relationships.
A recruiter doesn’t just ask “Does this person know Python?” They ask: Where did they use it? What for? How recently? In what context?
This is why real Agents — the kind that support or automate expert judgement — can’t just run prompts. They need to model the world they’re operating in. They need structure. And the best way to give them that structure? Not with rules. Not with chains of prompts. But with a graph — a living, queryable map of how things connect.
Before we discuss the in’s and out’s of a graph, let me first show you where this capability sits within the Repeatable Expertise pattern.

The steps in Blue above are the focus, but lets go over the whole flow as I’m using it.
Trigger
Something kicks off the flow — a file drop, a webhook, a Slack command, a DB transaction. In the case of the CV Screening Agent, it’s a number of file drops (CVs) in a folder.
Sourcing
The agent pulls relevant internal/external context — PDFs, knowledge bases, API calls, embeddings. Once again, in the Agent I am developing, this is sourcing the job specification from a database and client notes collected during meetings by the recruiter that reside in a CRM system.
At this stage there’s also two web search functions running - An education normaliser that takes the candidates training and education and seeks to approximate it to well-known courses and universities. The second scrape looks for current information of the salaries being paid for the specific role and seeking to understand sentiment in the market regards how hot (or not) the market is for these types of hires.
Reasoning
A looped LLM process runs — planning, tool use, evaluation, reflection, retry.
Ontology Alignment
At this point, the agent has pulled in data from multiple sources, parsed it, reflected on it, and started building internal representations of what it’s seeing — skills, roles, requirements, timelines, tools, experience.
But here’s the problem: Just because the LLM says something looks like a skill or seems relevant doesn’t mean it fits the actual domain. working with the ontology gives us the ability to justify why a decision has been made.
We’ll go over this in more detail in a minute and the code same at the end will help you see this in action.
Evaluation
With reasoning complete and ontology alignment done, the agent is almost ready to report. But before it does, it needs to evaluate its own output. Why?
Because LLMs make mistakes.
Because business decisions require trust.
And because judgement without accountability is useless.
You need traceability, repeatability, and risk tolerance baked into the loop. This stage in the process delivers that.
Formatting
Output is packaged - in this case, it’s a Word document report.
Transmission
The result is delivered to the human via both an email and the document being sent to the user in Slack.
This pattern is Agentic by design — not just a one-off GPT call.
And it’s not just theory. In fact, Bloomberg’s AI team uses nearly the exact same structure for their research analyst agent. As Anju Kambadur explained:
“Transcripts come in daily. We know what kinds of questions analysts care about. The agent pulls data, answers known questions, evaluates its answers, then pushes a structured summary. But the critical layer is evaluation. If the answer is wrong, the impact is enormous.”
What Is a Graph, and Why Should You Care?
If you’ve never worked with graphs before, here’s the simplest way to think about it:
A graph is a map of things (called nodes) and how they relate (called edges).
A Candidate is a node.
A Skill is a node.
“Candidate has skill” is a relationship — that’s an edge.
Now imagine building a map of a hiring decision:
Candidates link to the tools they’ve used
Skills connect to job requirements
Education links to universities, which have reputations
Employers link to roles, durations, industries, and technologies
That’s not a table. That’s a graph.
And it’s the only way to represent all that messy, fuzzy, human context in a way that an agent can reason over. Below is a screenshot of the graph that the code you’ll find below produces.
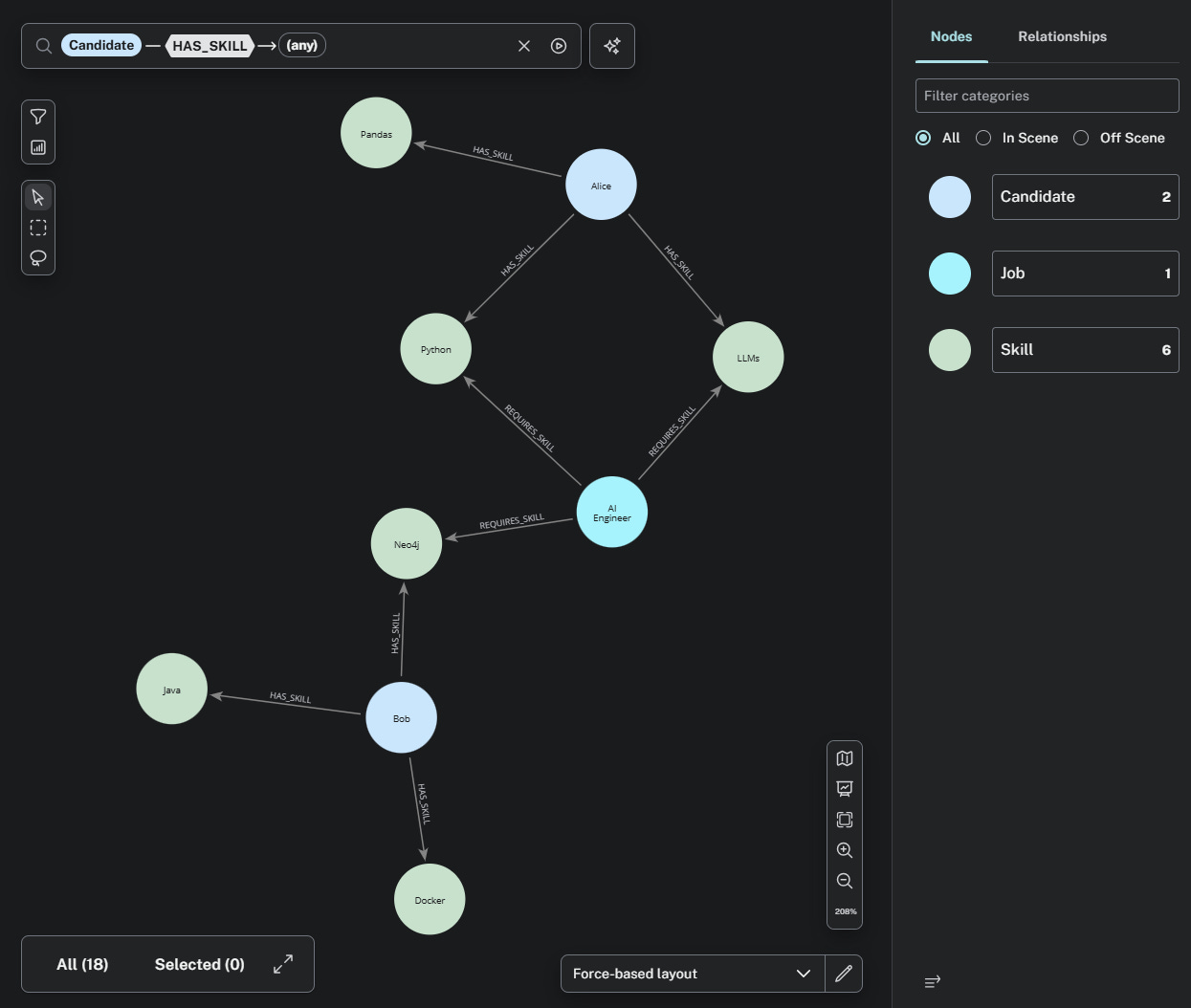
But What About Ontology?
Great question — and this is where most “let’s build an agent!” tutorials fall apart.
They show you how to call tools. They show you how to loop a prompt. But they don’t show you how to help the agent understand the world it’s operating in.
That’s where ontology comes in.
Ontology is the design of the graph. It defines what concepts exist, and how they connect.
You can think of it as your schema — not just for storing data, but for shaping reasoning.
In the CV Screening Agent, the ontology includes:
Entity types are Candidate, Job, Skill, Employer, Education
Relationships contains HAS_SKILL, REQUIRES_SKILL, WORKED_AT, STUDIED, INFERRED_FROM, SUPPORTED_BY
Rules & logic: “If a candidate used Hugging Face and PyTorch, infer NLP experience”
This structure lets the agent do multi-hop reasoning:
“This candidate worked at DeepMind → used PyTorch → built LLMs → has NLP experience → matches job requirement”
And because the graph is queryable and persistent (thanks to Neo4j), the agent can:
Build paths
Cite its decisions
Revisit earlier logic when it needs to re-evaluate
The ontology is what turns your graph from a data store into a thinking model.
How You Can Use Neo4j Aura to Power a Graph
You’ve seen how the graph fits into the Agent — but where does it actually live?
For that, I use Neo4j Aura — a fully managed, cloud-hosted graph database service.
It’s fast, secure, and supports everything I need:
Cypher query language (clean and readable)
Native Python drivers
Easy to spin up, no server management
Great for both development and production-scale use
Try it for Yourself
Below I’ve provided you with a basic Python script that will show exactly how this works. All you’ll need to do to run it is:
Follow the super simple steps and setup a free Aura account and get your neo4j credentials, you just need the URI, the Username and the Password which should ideally be added to your .env file.
A valid LLM API key, added to your .env file.
If you then run:
pip install neo4j openai python-dotenvYou should be good to go.
When you run the example code, you should get the following result.

You can check this in the Aura Explorer which will help you see why the LLM has provided the answer - the correct answer.

#########################################################################
# cv_graph_demo.py
#########################################################################
import os
from neo4j import GraphDatabase
from openai import OpenAI
from dotenv import load_dotenv
#########################################################################
# Load env vars (assumes Neo4j and OpenAI keys are in .env)
#########################################################################
load_dotenv()
neo4j_uri = os.getenv("NEO4J_URI")
neo4j_user = os.getenv("NEO4J_USERNAME")
neo4j_password = os.getenv("NEO4J_PASSWORD")
openai_key = os.getenv("OPENAI_API_KEY")
driver = GraphDatabase.driver(neo4j_uri, auth=(neo4j_user, neo4j_password))
openai = OpenAI(api_key=openai_key)
#########################################################################
# Graph Functions
#########################################################################
def setup_schema():
queries = [
"""
CREATE CONSTRAINT candidate_id IF NOT EXISTS
FOR (c:Candidate)
REQUIRE c.id IS UNIQUE
""",
"""
CREATE CONSTRAINT job_id IF NOT EXISTS
FOR (j:Job)
REQUIRE j.id IS UNIQUE
"""
]
with driver.session() as session:
for q in queries:
session.run(q)
def write_candidate(session, id, name, skills):
session.run("""
MERGE (c:Candidate {id: $id})
SET c.name = $name
WITH c
UNWIND $skills AS skill
MERGE (s:Skill {name: skill})
MERGE (c)-[:HAS_SKILL]->(s)
""", {"id": id, "name": name, "skills": skills})
def write_job(session, id, title, required_skills):
session.run("""
MERGE (j:Job {id: $id})
SET j.title = $title
WITH j
UNWIND $skills AS skill
MERGE (s:Skill {name: skill})
MERGE (j)-[:REQUIRES_SKILL]->(s)
""", {"id": id, "title": title, "skills": required_skills})
def get_skill_matches(session, job_id):
result = session.run("""
MATCH (j:Job {id: $job_id})-[:REQUIRES_SKILL]->(s:Skill)<-[:HAS_SKILL]-(c:Candidate)
RETURN c.name AS candidate, COLLECT(s.name) AS matched_skills
""", {"job_id": job_id})
return result.data()
#########################################################################
# LLM Scoring
#########################################################################
def evaluate_with_llm(job, matches):
candidate_text = "\n".join(
f"- {m['candidate']} (matched: {', '.join(m['matched_skills'])})"
for m in matches
)
prompt_template = """
You are a hiring agent. Based on the following job spec and candidate skill matches,
who is the best fit and why?
Job Title: {job_title}
Required Skills: {required_skills}
Candidates:
{candidates}
Output a 2-sentence judgement.
"""
prompt = prompt_template.format(
job_title=job["title"],
required_skills=", ".join(job["required_skills"]),
candidates=candidate_text
)
completion = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return completion.choices[0].message.content
#########################################################################
# Demo Run
#########################################################################
if __name__ == "__main__":
with driver.session() as session:
setup_schema()
# Dummy data for now
job = {"id": "job_001", "title": "AI Engineer", "required_skills": ["Python", "LLMs", "Neo4j"]}
candidates = [
{"id": "cand_001", "name": "Alice", "skills": ["Python", "Pandas", "LLMs"]},
{"id": "cand_002", "name": "Bob", "skills": ["Java", "Neo4j", "Docker"]}
]
write_job(session, job["id"], job["title"], job["required_skills"])
for cand in candidates:
write_candidate(session, cand["id"], cand["name"], cand["skills"])
matches = get_skill_matches(session, job["id"])
print("Skill Match Results:", matches)
result = evaluate_with_llm(job, matches)
print("\nLLM Judgement:\n", result)
driver.close()Summing Up: Why This Matters
Let’s zoom out.
You’ve now seen an Agent architecture that goes far beyond prompting:
It reasons over real data
It aligns fuzzy output to structured domain logic
It uses an ontology to build a model of understanding
It traces its own decisions and justifies them
This is not just about building chatbots or showing off what GPT-4 can do.
It’s about encoding Repeatable Expertise — the kind of structured thinking that defines your best recruiters, analysts, lawyers, or investigators — and wrapping that expertise inside an agent that works 24/7, scales on demand, and explains its reasoning.
That’s what the Repeatable Expertise Pattern unlocks.
Where You Go From Here
You don’t need to be building a recruitment tool to use this pattern.
If your domain involves:
Structured documents (CVs, contracts, applications)
Reasoning over facts and evidence
Comparing things (candidates, offers, risks, vendors)
Or reporting outcomes to humans…
Then you can adopt this graph-powered approach in your own system.
You now have:
The conceptual foundation (ontology, judgement, reasoning loops)
A reference architecture (trigger → source → reason → align → evaluate → report)
And a runnable code sample to play with
So what will you build? Comment below if you feel like sharing.
Until the next one, Chris.
Enjoyed this post? Please share your thoughts in the comments or spread the word by hitting that Restack button.