



If you’ve ever sat in an meeting debating “Should we use GPT-4, Claude, or something open source?”, this system ends the guesswork.
This is your evidence-based LLM selection meta-prompt — a pipeline that evaluates models across cost, latency, reasoning, context length, compliance, and ecosystem fit, and produces a structured HTML artifact with everything an engineer or architect needs to justify their decision.
No spreadsheets.
No Slack arguments.
Just one deterministic, audit-ready recommendation file.
Why You Need This
Every month brings new foundation models.
Each claims to be “the smartest” or “the cheapest.”
Without a clear framework, teams make emotional or anecdotal choices.
This system turns that noise into signal. It:
🔎 Searches the live web for verified sources (model cards, benchmarks, pricing, compliance docs)
⚖️ Scores each candidate using weighted criteria you define
🧩 Ensures vendor diversity (≥ 2 proprietary ecosystems + ≥ 1 open-source)
🔒 Checks domain guardrails (HIPAA, GDPR, SOC 2, PCI DSS, etc.)
🧠 Produces a downloadable HTML artifact containing:
A comparison table with features, rationale, resources, and scores
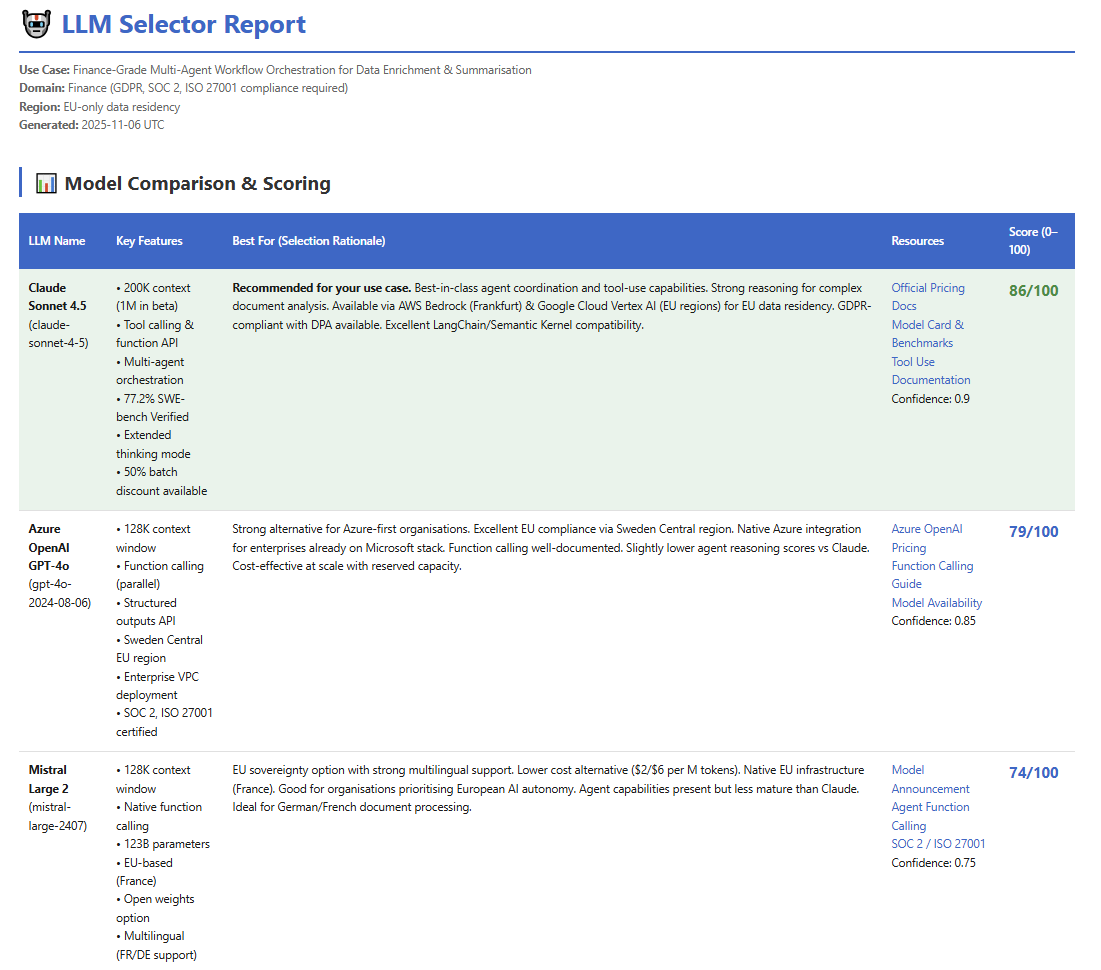
A recommended solution block with trade-offs

Implementation steps (SDK, auth, retries, eval harness, rollout)

Full provenance: timestamps, confidence ratings, and compliance disclaimers
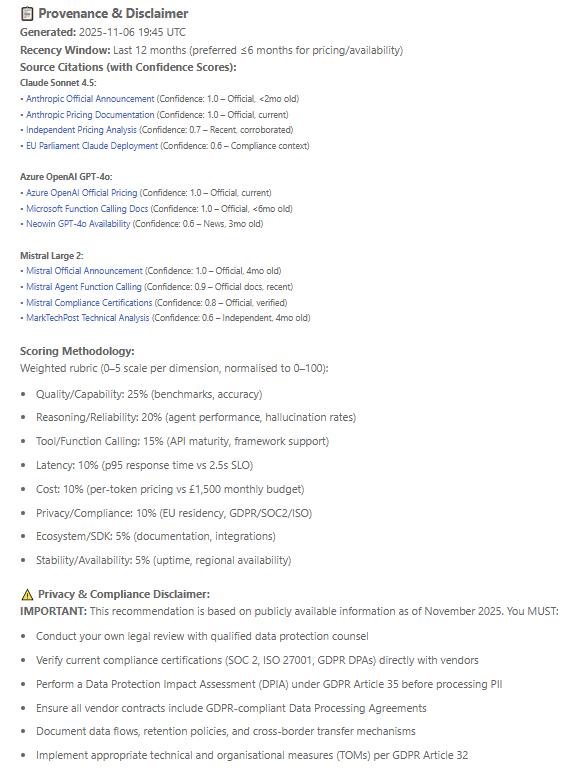
It’s everything you’d expect from a senior AI architect — automated.
How It Works
Open your conversational AI - Claude is best for this prompt.
Paste the full LLM Selector meta-prompt.
Answer the 10 onboarding questions.
Wait ~3 minutes for research and scoring.
Download the generated HTML artifact.
Optional: feed it back your model evaluation results — it’ll update confidence and recommendations automatically.
Who This Is For
✅ Engineering and architecture teams comparing models for deployment
✅ MLOps teams standardising on evaluation criteria
✅ Consultants producing AI feasibility studies
✅ Compliance or security teams validating vendor claims
✅ Product owners balancing performance vs cost
Who This Isn’t For
❌ Casual users asking “Which model is smarter?”
❌ Anyone unwilling to share objective requirements
❌ Situations needing certified clinical or legal advice
Why This Matters
Selecting an LLM is now an engineering decision, not an art. Costs, latency, reasoning ability, and data laws are measurable.
The LLM Selector turns that measurement into a repeatable standard.
Because picking the right model shouldn’t feel like a coin toss — it should feel like compliance, design, and strategy finally working together.
Grab the LLM Selector meta-prompt and end the “which model?” debate for good.